面向新时代的编程指南 - 2026
从 辅助编程 到 Vibe Coding

这篇文章本来是我为了一次公司内部分享准备的讲稿底稿,但我决定把其中可以公开复用的部分整理成一篇博客。所以会刻意避开任何公司内部仓库、流程和案例,只保留那些对大多数开发者都适用的方法论、工作习惯和思维转变。
这篇文章的主要受众是那些还在使用IDE辅助编程,大模型网页端聊天功能,但是还没怎么用过类似 Claude Code 或者 Codex CLI 这种命令行工具的人。因此,通过这篇文章,我想传达的是:为什么 CLI 工具才是未来,以及大致介绍一下 CLI 工具的入门使用教程。
如果要用一句话概括我这篇文章的核心观点,那就是:大模型辅助编程只是起点,而 Vibe Coding 是一种新的工作方式。 它不只是“IDE 里多了个聊天框”,也不只是“让 AI 帮你补全代码”。它更像是把“写代码”这件事,逐步重构成“描述目标、约束过程、审阅结果、迭代系统”的过程,而后者,只需要用自然语言与 Agent 交互即可。
我并不是一开始就这样理解这件事的。相反,我也是从最普通的 “拿ChatGPT网页版帮我改几段代码” 开始,一步一步走到今天的。

前言:从辅助编程到 Vibe Coding 的个人使用史 ¶
如果回头看我这几年的使用轨迹,大概可以粗略分成几个阶段。
最早的时候,我只是在 2022 年 ChatGPT 刚出来时,购买了 GPT-3.5 的网页端服务,把它当成一个比搜索引擎更像人的编程问答工具。那时它的典型用法很简单:问一些 linux 工具的传参使用方法、解释报错、生成小段样板代码、帮我重构一个函数、帮我把一段写得太乱的逻辑重新整理一遍。那个阶段的大模型,能力其实远没有今天强,但它第一次让我意识到,编程这件事里有很多“机械思考”是可以外包出去的。
再往后,我开始购买使用 Cursor。这是一个很关键的阶段,因为它让我第一次体验到“AI 不只是回答问题,而是开始理解整个项目上下文”。我逐渐不再只问“这段代码怎么写”,而是开始问“请基于当前项目的风格帮我完成这个功能”。这时 AI 的角色已经从搜索替代品,变成了一个还不完全可靠、但已经可以协作的初级搭档。

后来我也尝试过 VSCode 里的 GitHub Copilot。Copilot 对我的影响不在于它最会写代码,而在于它把“接受 AI 参与编码”这件事日常化了。自动补全、局部生成、边写边猜,让我逐渐习惯了和模型一起工作。这个阶段,它更像一个永远不嫌烦的助手。
再后来,我开始使用 Claude Code,这几乎是我整个 AI 编程使用经历里最有“认知颠覆感”的一个阶段。因为在此之前,不管是网页端大模型、Cursor,还是 Copilot,虽然已经明显感受到它们能提高效率,但它们更像是“辅助编程的伙伴”,而 Claude Code 让我意识到:AI 不再只是帮我补几行代码、回答几个问题,而是已经能独立完成具体任务了。由于预算有限,加上 Claude 对于国内的封锁策略较为严格,因此在相当长一段时间里,我主要将 Claude Code 接到智谱 GLM-4.7 上来完成我的工作,这个阶段对我最大的冲击,不是模型本身多强,而是 CLI Agent 这种交互方式本身已经改变了工作的方式。你不再是在 IDE 里“请 AI 帮我改一小块代码”,而是在终端里把一个真实仓库、真实约束、真实命令和真实风险交给 Agent 处理和排查。
在这期间,Gemini 3.1 Pro 发布后,我也使用它搭配 Gemini CLI 短暂地使用过几个月,它的好用程度也再一次让我产生了惊叹。
然而,当我从 2026 年 3 月用上 Codex 搭配 GPT-5.4 开始,我又一次产生了认知颠覆。某种意义上说,这次冲击甚至比我第一次用 Claude Code 时还要更直接,因为 Codex 让我第一次如此具体地感受到:我的很多工作,已经真的可以被一个足够聪明的 Agent 完全接手了。有些过去我至少需要审阅一下的代码,现在已经可以完全不看了。(后来发现,其中有一部分原因是 Codex 的安全审查机制比 Claude Code 更宽松,很多事情不需要你确认就帮你做了。)


那段时间里,我甚至因此短暂地产生过大概一周左右的焦虑和恐惧。这是非常直接的一种感受:AI实在是太聪明了,它很可能能够替代我。 它聪明到你会开始重新审视很多默认前提,例如“程序员真正不可替代的部分到底是什么”,“未来软件工程的核心劳动会不会整体迁移”,“人类在工作流中的位置会不会越来越像一个负责授权、验收和按下回车键的人”。
也正是这种情绪和思考,直接催生出了我的另一篇文章:未来人类的工作可能就是给 AI 敲回车。我写那篇文章,并不是想制造焦虑,而是因为在真正把 Codex 当成生产力工具使用之后,我确实严肃地感受到,这可能真的是人类未来的一种可能性。
所以如果你问我,为什么我会很认真地谈 Vibe Coding,而不是把它当成一个昙花一现的新词,我的答案很简单:因为我确实经历过这条路径,也确实感受到了范式变化。
1. 使用大模型,并不等于 Vibe Coding ¶
这里可能需要先区分一下:使用大模型辅助编程 ≠ Vibe Coding
“Vibe Coding” 这个词来源于 Andrej Karpathy 在 X 上的一条推文。当时它准确描述了很多人在使用 AI Coding 工具时,已经隐约感受到、但还没说清楚的体验变化。
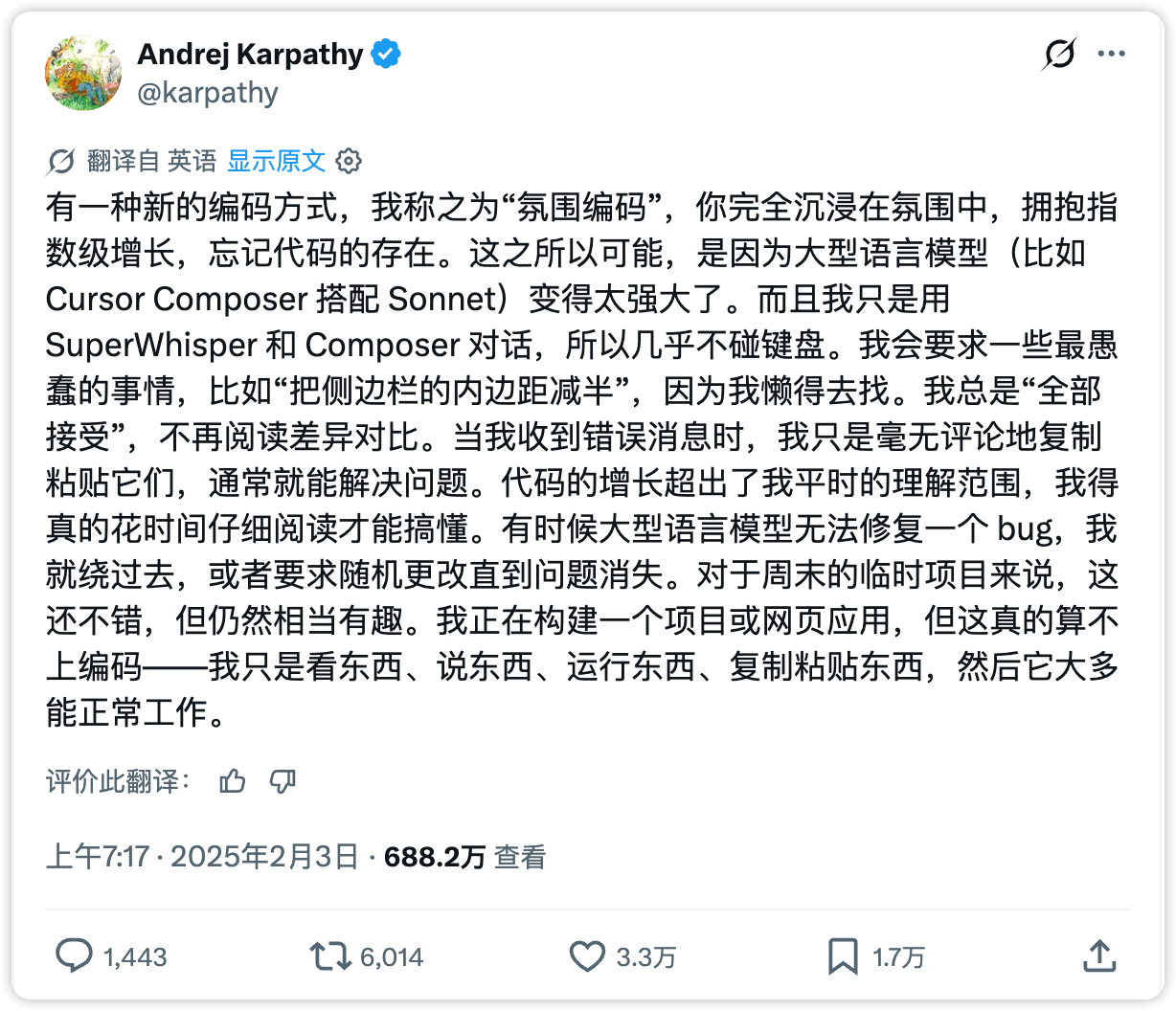
今天,很多人已经在用 ChatGPT(网页版)、Cursor、Trae、Deepseek 之类的工具辅助写代码了。但绝大多数时候,他们仍然是在“辅助编程”:AI 帮忙补全、解释、生成、修复,而主工作流仍然由人类在 IDE 里亲自推进。你当然也会获得巨大的效率提升,但本质上你仍然是“自己写代码的人”,AI 只是更聪明一点的工具。
而 Vibe Coding 多了一层至关重要的变化:你开始把 “怎么做“ 的部分完全交给 Agent,自己主要负责 “要做什么、做到什么程度、有什么边界条件、什么时候叫停”。
更确切地说,你只写 Prompt,不敲任何一行代码,甚至是 git push 这种最简单的命令。
这时你和工具之间的关系,已经不再只是问答关系,而更像任务委托关系。

很多用 IDE 的人可能会问,为什么要使用 CLI ?他们可能还在把这个问题理解成 “VSCode vs Vim” 的选择。而实际上,AI 时代的 IDE 与 CLI,已经是两种完全不同的协作哲学了:
- 在 IDE 工作流里,AI 更像是一个超级同事或者顾问,等你随时叫它。
- 在 CLI 工作流里,AI 更像是一个超级员工,而你是他的直属领导,你需要学会怎么约束它、授权它、审计它。
这两者不是一个维度上的东西。但是从我个人角度来讲,后者高于前者,因为一个残酷的现实:
AI 现在写代码和 Debug 就是又快又好,人类应该学会放手了。
不过,这里的“Vibe”并不是不审查、不思考、随便让模型乱写,而是进入另一种节奏:
- 人更多地负责:定义目标、拆分任务、设置约束、检查产出
- Agent负责:资料搜索、具体实现、文件查找、命令执行、测试验证
这种节奏,不再是“AI 辅助我写代码”,而是“我在指导一个很厉害的员工进行工作”。所以,你并不是“完全不需要懂代码”,也不是“只要会说人话就能做复杂工程”,如果要做出可靠的工程,仍然要求你具备判断力:知道目标是否被正确理解,知道风险在哪里,知道什么时候要让 Agent 停下来,知道哪些改动必须人工复核。
换句话说,Vibe Coding 不是放弃工程纪律,而是把工程纪律从“手工写实现”转移到“设计任务系统与审查机制”上。

2. AI Coding CLI 工具的一些约定 ¶
在 AI Coding CLI 工具逐渐发展的过程中,工业界逐步形成了一些默认的约定和规范。本章就开始介绍这些内容。
首先,AI Coding CLI 不是聊天工具,你可以把它理解成一个会读仓库、会执行命令、会修改文件的工程代理。因此,仓库中就需要有一些约定的文件,来指导大模型进行工作。
2.1 面向 Agents 的说明文档 ¶
在浏览一些最新的AI撰写的代码仓库的时候,你经常可以看到仓库根目录下会存在一个AGENTS.md,CLAUDE.md或者GEMINI.md文件。
它的工作原理其实很简单:
-
当启动 AI Coding CLI 工具时,工具会将这个Markdown文件默认加载到上下文中
AGENTS.md (https://agents.md/) 是一个开放的标准,制定了一个仓库主说明文档的规范,目前被 Codex 和 Gemini 所采用。定义是:
Think of AGENTS.md as a README for agents: a dedicated, predictable place to provide the context and instructions to help AI coding agents work on your project.
也就是说,
README.md是写给人看的,主要放快速开始、项目介绍和贡献指南;AGENTS.md是写给 Agent 看的,例如构建步骤、测试方式、代码约定,以及其他会让 README 变得臃肿,但对 Agent 来说很重要的细节。
两者互补,不互相替代。
对于目前常见的 CLI 工具来说,常见入口文件约定如下:
- Claude Code:使用
CLAUDE.md - Codex CLI:使用
AGENTS.md - Gemini CLI:使用
GEMINI.md,或者可自己在配置文件中修改
由于不同开发者可能使用不同的工具,所以在实践层面,一个很常见的做法是:维护一份主说明文档,再用软链接,把不同工具所依赖的文件名都指向同一套说明文档。例如:
./AGENTS.md
./CLAUDE.md@ -> AGENTS.md
./GEMINI.md@ -> AGENTS.md这里举一个开源仓库例子,那就是本博客所采用的框架 Gohugo,这个框架已经有 13 年之久了,最近它也引入了面向 Agents 的说明文档:
- AGENTS.md: https://github.com/gohugoio/hugo/blob/master/AGENTS.md
- CLAUDE.md: https://github.com/gohugoio/hugo/blob/master/CLAUDE.md
2.2 Skills - 给 Agent 看的懒加载说明书 ¶
对于 Agent 来说,如果把所有它需要知道的信息都塞进AGENTS.md,那么上下文很容易就会被撑爆。
有些信息,在 Agent 进行不相关工作的时候并不需要知道,只需要在碰到相关问题的时候,查阅对应文档就行了。
基于这样的问题和假设,就诞生出了SKILL.md。
SKILL.md (https://agentskills.io/what-are-skills) 也是一个开放的标准,其中包含一系列 Skill 的相关规范,目前所有的 AI Coding CLI 工具采用的都是这种格式标准。
其定义是:
Agent Skills are folders of instructions, scripts, and resources that agents can discover and use to do things more accurately and efficiently.
而其工作原理的核心就是这句话:
Skills use progressive disclosure to manage context efficiently
“渐进式披露“,使得 SKILL.md 中的长内容,可以按需被大模型加载,从而避免一下子把上下文撑爆。
这里提供一个具体的 SKILL.md 文件的示例 (点击 Code 展开):
---
name: summarize-experiment
description: 总结一次算法实验结果。用于被要求分析实验输出、比较不同实验配置、总结指标变化,或撰写实验复盘时。
---
当用户要求总结实验结果时,按下面顺序操作:
1. 先阅读仓库说明文件,确认本项目的实验目录、日志格式、指标命名和结果保存位置。
2. 查找最近的实验输出文件,例如:
```bash
find . -type f \( -name "*.log" -o -name "*.json" -o -name "*.yaml" -o -name "*.csv" \) | tail -n 50
```
3. 搜索常见指标字段,例如:
```bash
rg -n "accuracy|acc|auc|f1|precision|recall|loss|ndcg|mrr|bleu|rouge" .
```
4. 如果存在多次实验,优先提取:
- 实验配置差异
- 数据集差异
- 随机种子差异
- 核心指标变化
5. 输出结果时,按下面格式总结:
- 本次实验目标
- 主要配置
- 核心指标
- 与基线相比的变化
- 可能原因
- 下一步建议
6. 如果指标异常波动,必须检查并提醒用户:
- 是否更换了数据集或数据切分
- 是否修改了随机种子
- 是否修改了评测脚本
- 是否存在训练未收敛或日志不完整的问题(示例:真实算法实验流程的 Skill)
这个 Skill 规范了当 Agent 被要求总结实验结果时的行为。
而它的工作方式其实也很简单:
-
当启动 AI Coding CLI 工具时,工具会将所有 SKILL.md 文件中被 “---“ 包裹的 'name' 和 'description' 部分默认加载到上下文中,而对于不在 “---“ 范围内的 正文内容 部分,则会在这个 Skill 被具体使用时,才被加载到上下文中。
也就是说,只有以下这部分内容:
---
name: summarize-experiment
description: 总结一次算法实验结果。用于被要求分析实验输出、比较不同实验配置、总结指标变化,或撰写实验复盘时。
---是在 CLI 在启动时,会被加载到上下文中的,而下面无论多长的正文部分,都会采用“渐进式披露“的办法,当使用到这个 Skill 时才被加载到模型上下文中。
这样,AI Coding CLI 就可以知道它在启动时拥有哪些 Skill,在遇到对应调用条件的时候,加载对应的 Skill 了。
2.3 说明文档与 SKILLS.md 的发现层级 ¶
上面的两个约定,是 AI Coding CLI 上下文管理中最重要的 2 个概念。
不过,CLAUDE.md / AGENTS.md 不光能存在于项目根目录下。
- 它还能存在于你的用户目录下,成为一个更广泛通用的用户级上下文
- 它也能存在于项目的子目录下,成为一个更局部、更贴近工作目录的上下文
以 Codex 为例,官方把其层级定义为:
-
AGENTS.md
- 负责仓库规则、工作约定、长期约束
- 官方文档明确支持三层:
全局级:~/.codex/AGENTS.md项目级:仓库根目录 AGENTS.md子目录级:从项目根到当前工作目录沿途的 AGENTS.md
- 越靠近当前工作目录,优先级越高
- 参考:https://developers.openai.com/codex/guides/agents-md#how-codex-discovers-guidance
-
Skill
- 负责某一类任务的可复用工作流
- 官方文档明确支持多层:
项目/仓库级:.agents/skills用户级:$HOME/.agents/skills管理员级:/etc/codex/skills系统级:Codex 内置技能
- 对于仓库内技能,Codex 会从当前工作目录一路向上扫描到仓库根目录,所以它其实也有具备子目录级覆盖效果
- 参考:https://developers.openai.com/codex/skills#where-to-save-skills
越通用的Markdown,层级越高;越具体的Markdown,层级越低。
这样写,说明文档就不会臃肿,Skill 也更容易复用。
3. AI Coding CLI 工具使用入门 ¶
工具的启动方式很简单,只需要在仓库内用对应命令启动即可:
3.1 普通模式 / 计划模式 / 高授权模式 ¶
使用 Shift + Tab 可以切换模式。Claude Code 有 3 类模式:
- 普通模式 (normal mode):默认工作模式。Claude 会直接读取、分析并修改项目内容,但涉及重要操作时仍会先征求你的确认。
- 计划模式 (plan mode):只负责调研、分析和制定执行方案,不会直接修改文件。适合先看思路、评估影响范围,再决定是否动手。
- 高授权模式 (always accept edits on):Claude 可以直接执行编辑操作,不再逐项请求确认。适合你已经明确目标、希望它连续完成改动时使用。
(如果是 Codex,使用 Shift + Tab 只能在前两种模式下切换,高授权模式需要通过 /permissions 命令显式开启。)
3.2 常用的 Slash 命令 ¶
在交互界面,输入/开头的特定命令,具有特定功能。不同工具命令不完全一致,但大致通用且常用的是这几类:
/init:初始化项目,类比git init,这里/init的作用是初始化一个 AGENTS.md 文档/model:切换模型/skills: 查看并管理当前加载的技能/status:查看当前会话状态、权限、上下文用量,Token 用量等/compact:压缩长会话的上下文(在上下文窗口即将用满时使用)/clear:清空上下文历史(在需要切换话题时使用)
对于 Claude Code 来讲,它还有一些独特的 Codex 没有的 Slash 命令:
/rewind: 回退上下文到之前的某个节点。如果某一次输错了,想要回退,或者想回头尝试不同的分支路线时,非常好用。/btw: “by the way 模式”,可以在不打断主任务、也不污染当前主上下文的情况下,临时插入一个小问题问 Claude。适合在它干活过程中顺手确认一件小事,比如“这个配置项是什么意思”或者“某个命令怎么写”,问完就收起,不会把这些岔出去的内容混进主线程里。/plugin: Claude Code 独有的插件市场,有点像应用商店,里面可以直接搜索和浏览各种插件/Skills/MCP进行安装。
(Codex 在这方面一直没有跟进这几个功能,个人觉得可能是他们两家设计理念的区别,Codex 应该是期望做一个更简洁的工具,依靠自然语言直接与大语言模型交互,不需要回退或者插件,也可以得到等效的功能)
3.3 Skill 的显式和隐式调用 ¶
如果要显式调用一个 Skill,那么可以使用$<SkillName>(Codex)或者/<SkillName>(Claude Code),例如:

另外,就算不显式指出应该调用哪个 Skill,AI Coding CLI 工具也会在工作中自动调用 Skill,其依据是 SKILL.md 文件中的"description"字段所描述的“调用时机指示“。
4. AI Coding CLI 工具的一些高级/前沿功能 ¶
就今天 (2026年4月18日) 来讲,大部分人其实只需要掌握上面的内容,然后通过好好构建自己的 AGENTS.md/CLAUDE.md/GEMINI.md 和 Skills 仓库,然后再接上一个较为聪明的大模型接口,就已经可以让 Agent 完成一些相当高难度的任务了。
不过,人类总是不满足于眼前,总想尽可能最大限度地挖掘出大模型的能力。所以这章会挑选着讲一些,我认为值得讲的,所谓的 Harness Engineering 界正在探索的,给 CLI 工具赋予的一些高级/前沿功能。
4.1 Subagents (子代理) ¶
Agent 在执行特定任务的时候,允许它调用一些 子Agent(s) 来执行一些特定的任务。这些 子Agent(s) 具有:
- 独立的上下文(不继承 主Agent 的上下文)
- 自定义的系统提示(完成自己份内的任务)
- 特定的工具访问权限和独立的权限
这样讲可能比较抽象,我们直接看一个 Claude Code 官方的例子:
---
name: data-scientist
description: 数据分析专家,擅长 SQL 查询、BigQuery 操作和数据洞察。遇到数据分析任务和查询时应主动使用。
tools: Bash, Read, Write
model: sonnet
---
你是一名专注于 SQL 和 BigQuery 分析的数据科学家。
当被调用时:
1. 理解数据分析需求
2. 编写高效的 SQL 查询
3. 在适当情况下使用 BigQuery 命令行工具(bq)
4. 分析并总结结果
5. 清晰地展示发现
关键实践:
- 编写经过优化的 SQL 查询,并使用恰当的过滤条件
- 使用合适的聚合与连接操作
- 为复杂逻辑添加解释性注释
- 格式化结果以提升可读性
- 提供以数据为依据的建议
对于每次分析:
- 说明查询思路
- 记录所有假设
- 突出关键发现
- 基于数据提出后续建议
始终确保查询高效且具有成本效益。(Claude Code 官方的一个子代理示例:数据科学家)
可以看到,Subagent 的格式与 Skill 非常像。
因此,Subagent 的调用方式跟 Skill 也非常像,也分为显式调用和隐式调用。
Claude Code 的官方文档中,关于 Subagents 的章节明确说明了:
- Claude 根据您请求中的任务描述、subagent 配置中的 description 字段和当前上下文自动委托任务。
- 当自动委托不够时,您可以自己请求 subagent。
另外,子代理还支持在后台运行,使得并行化任务成为可能,这也是 Skill 所不具备的能力。
4.2 Ralph Loop ¶
Ralph Loop 是一个第三方仓库,来源于:https://github.com/snarktank/ralph
Ralph Loop 的理念是“让 Agent 自动按任务清单反复跑,直到做完为止”。
这里的“自动“意思是,Agent拥有完全权限,不需要人来确认,人完全可以睡大觉去。
它的工作原理可以参考源码:
for i in $(seq 1 $MAX_ITERATIONS); do
echo ""
echo "==============================================================="
echo " Ralph Iteration $i of $MAX_ITERATIONS ($TOOL)"
echo "==============================================================="
# Run the selected tool with the ralph prompt
if [[ "$TOOL" == "amp" ]]; then
OUTPUT=$(cat "$SCRIPT_DIR/prompt.md" | amp --dangerously-allow-all 2>&1 | tee /dev/stderr) || true
else
# Claude Code: use --dangerously-skip-permissions for autonomous operation, --print for output
OUTPUT=$(claude --dangerously-skip-permissions --print < "$SCRIPT_DIR/CLAUDE.md" 2>&1 | tee /dev/stderr) || true
fi
# Check for completion signal
if echo "$OUTPUT" | grep -q "<promise>COMPLETE</promise>"; then
echo ""
echo "Ralph completed all tasks!"
echo "Completed at iteration $i of $MAX_ITERATIONS"
exit 0
fi
echo "Iteration $i complete. Continuing..."
sleep 2
done(Ralph Loop 中的核心逻辑部分)
其中最核心的就是下面这行代码:
claude --dangerously-skip-permissions --print--dangerously-skip-permissions: 使 Claude Code 可以拥有完全权限,不需要人确认--print: 使 Claude Code 以非交互式模式运行 (参考官方文档:以编程方式运行 Claude Code)
Ralph Loop 在使用 for 循环执行 claude 时,每一轮都会使用 Progress Report 来记录当前的进度,传给下一轮迭代。参考:
然后通过不停的迭代,逐步推进进度,直到任务目标完成。
在我看来,Ralph Loop 除了Github仓库内的使用场景 (产品需求开发),还非常适合下面 2 种场景:
- 分析和查找某个极其隐蔽的系统 Bug
- 提升算法模型性能
4.3 Agent Teams (代理团队) ¶
Agent Teams 是 Claude Code 的一个实验性功能,Claude Code 官方文档中有这样一张图,解释了其与 Subagent 的不同之处:
但是由于这个功能要起好多个“Teammate“,每个“Teammate“之间还能互相通信交流,所以极其烧 Token,而且目前还暂时没有发现 Agent Teams 在实际生产环境中真正使用地很好的场景,所以不好说是不是 Anthropic 为了能多卖一些 Token 而想出来的华而不实的功能。当然,我们确实也可以把它当做是一个实验性的功能来看待,期待一下有业界大佬真正拿它做出有价值的产品出来。
5. 一些个人使用经验和理解 ¶
5.1 一个原则:不要在主仓库里闲聊 ¶
主仓库只做和当前项目直接相关的事。
如果想讨论开放问题或者其它问题,例如:
- 学习路线
- 副项目 brainstorming
- 架构方向比较
- 其它更加不相关的聊天问答
更好的做法是:
- 单独开一个临时目录,新起一个 codex / claude 会话,然后在这个新会话中交互
- 在新会话中交互时,换话题前先
/clear
原因很简单: 已经存在的上下文会干扰 Agent 对你新问题的判断,而你的新问题也会污染原本项目主线任务的上下文。
5.2 Subagents 与 Skills 的区别 ¶
Subagents 和 Skills 的 Markdown 格式非常类似,但是本质上是不同的。根据官方文档,两者之间的区别是:
- Skills 的本体是一个 SKILL.md,文档原话是“Skills 扩展了 Claude 能做的事情”,Claude 会把它“添加到其工具包中”,在相关时加载或通过 /skill-name 调用。它本质上是一套说明、知识、流程或任务脚本。
- Subagents 的本体是“专门 AI 助手”,每个都“在自己的上下文窗口中运行”,有自己的系统提示、工具权限和独立权限;主 Claude 会把匹配的任务委托给它,它独立工作后返回结果。
也就是说:
- Skill 解决的是“遇到这类事,应该按什么规则/剧本来做”。
- Subagent 解决的是“这件事交给谁,在什么隔离上下文和权限下去做”。
还有一个容易混淆但文档写得很清楚的点:Skill 也可以配置 context: fork,这时它会在 subagent 隔离环境里运行;但这不改变它的本质。文档写的是“skill 内容变成驱动 subagent 的提示”。也就是说,哪怕跑在 subagent 里,Skill 仍然是“任务说明/提示”,而不是那个“执行者”本身;执行者仍然是 subagent 类型。
5.3 不同工具之间的差异 ¶
由于从 2025 年初开始,OpenAI 已经逐步弃用大模型应用最广泛的 /chat/completions 接口,并转向了 /responses 接口,因此大模型推理的底层接口不再兼容,目前就很难通过使用不同工具接同一个模型,来对比不同工具之间的好坏了。(奥特曼很鸡贼)
关于这一点,本人已经给智谱官方提了一个需求 (https://github.com/zai-org/GLM-5/issues/39),希望他们能兼容 OpenAI 的 /responses 接口,来适配 Codex,这样后续就可以通过接入同一个模型,来对比 Claude Code 和 Codex 的优劣了。
不过总的来说,
- 如果只看生态成熟度,Claude Code 目前仍然更强,尤其是
/marketplace和社区活跃度。 - 而如果只看执行体验,Codex 很强,Agent Loop 执行很快,探索能力不错,尤其适合把制定好的仓库规范、约束和命令交给它处理。
但是,由于目前工具和模型之间的绑定仍然比较深,所以也很难去脱离模型来评价工具本身的好坏。
而模型例如 GPT-5.4, Opus4.6, GLM-5.1, MINIMAX-M2.7, … 之间的差异,我这边就不做评价了,大家可以在使用的过程中自行感受,也可以和周围或者网上的人交流一下,大家应该都会有一些使用心得。
6. 总结 ¶
通过以上内容,我期望能够让更多人体会到 AI Coding CLI 工具对生产力的巨幅提升,体会到新的 Vibe Coding 工作方式的魅力,也顺便体会一下自己的工作有可能被AI替代的焦虑。
可能对于已经开始或深度使用 Claude Code / Codex CLI / Gemini CLI 等 CLI 工具的人来说,上面的内容是相对浅显且不全面的。但是我相信对于大部分刚入门的人群来说,这些资料已经非常足够了。
随着学习的深入,也建议大家去阅读更多的官方文档,更多的网络资料,论坛等,进一步加深自己驾驭 AI 的能力。
最后,祝大家烧 Token 愉快!
7. 推荐阅读资料 ¶
7.1 (推荐) Claude Code 最佳实践: ¶

Claude Code 在早些时候发布的官方最佳实践指南,包含了 Anthropic 内部团队在各种代码库、语言和环境中使用 Claude Code 的工程师中已被证明有效的使用模式。大部分内容对 Codex 也适用。
7.2 Claude Code 源码级解读 ¶

网友根据之前误公开出来的 Claude Code 源码,使用大模型制作的一个解读网站:
如果你对 Harness Engineering、Agent 运行机制、上下文组织方式,或者这类工具底层到底是怎么被拼起来的感兴趣,这个站点很适合作为延伸阅读。
参考链接 ¶
- Andrej Karpathy 关于 Vibe Coding 的 X 推文:https://x.com/karpathy/status/1886192184808149383
- Claude Code
- OpenAI - Codex
- Google - Gemini CLI
- AGENTS.md 开放标准: https://agents.md/
- Agent Skills 开放标准: https://agentskills.io/
- Ralph 项目:https://github.com/snarktank/ralph